Pagination Ordered by Secondary Keys on Sharded Stores

A common design for content display, pagination partitions information into multiple pages and serves one at a time. We have seen it in search results, message history, and cascading news feed, etc. It shrinks the payload of server response and therefore reduces the response latency.
It is often the case that the table in question (1) has a primary key, such as orderId, itemId, msgId, and (2) pagination is sorted on some secondary key such as time, price, popularity. When the table is small, indexing on the secondary key plus the SQL offset/limit in will do.
For higher throughput, the table might be sharded on a partition key, and each table running on different nodes governs a disjoined segment of key space. The partition key is often chosen as the primary key, which makes pagination using secondary keys much more challenging, because none of the nodes have a global view of the entire dataset. We describe three approaches to this problem.
External Merging
Say the client wants the 3rd page sorted by time from the storage of two shards. Entries are likely interleaved between the two shards, but an extreme case would be that the latest 3 pages all reside on either of the shards. For correctness, we must read the first 3 pages (not just the 3rd) from each shard, then merge the responses in memory on service tier and return the 3rd page from the total order.
This may be the most obvious solution, but it does not scale. Imagine the client wants the 100th page and each page has 200 entries. Or you have got multiple shards that are geo-distributed. Now you have to read 20000 entries from each shard and then suffer the high network latency as well as high CPU usage.
Compromise: No Skipping but only Next Page

The limit on the page index query only allows the client to visit the next page (e.g. your facebook news feed). This is essentially an optimization over external merging in that each shard always returns only one page for each request. The coordinator/aggregator merges the result and records the highest value of the secondary key from each shard. On the fetching next page, such value is used as the selection condition to get the next load of one page from each shard.
Lookup Twice
Assume each page has 5 rows and we were to get the 200th page. The SQL query is
1
select * from T order by time offset 1000 limit 5;
If there are 3 shards in total, rewrite the query as
1
select * from T order by time offset 333 limit 5;
and the following is the result from each shard.
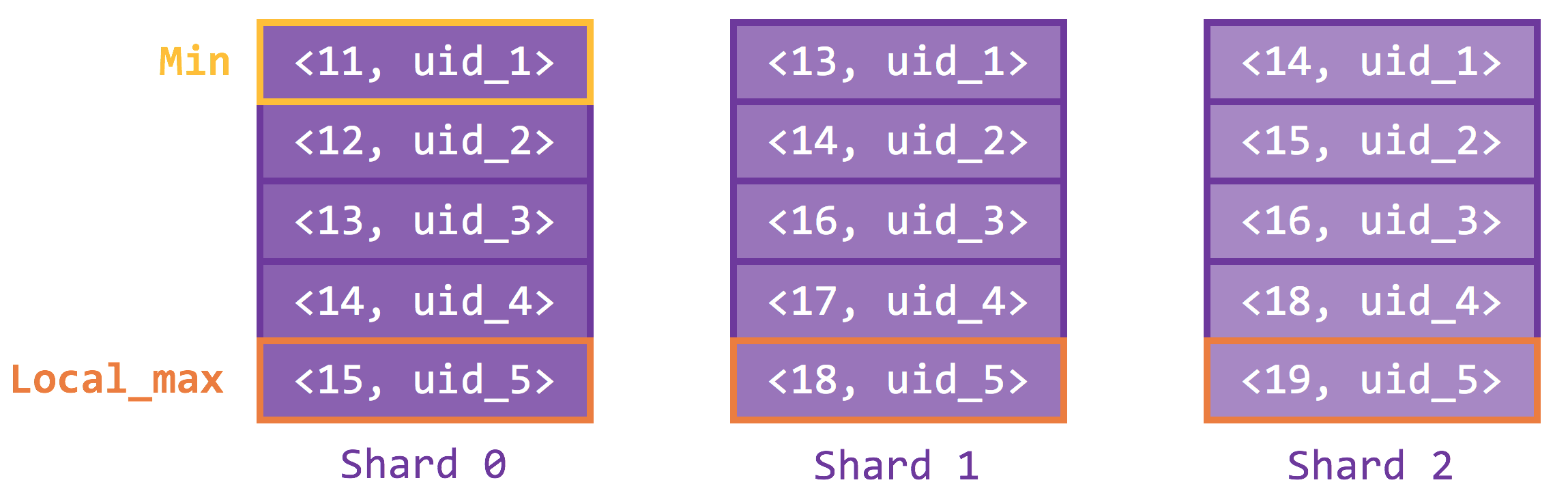
Then, do a range query using the between directive, which starts from the min and ends at the local_max. The results are shown below.
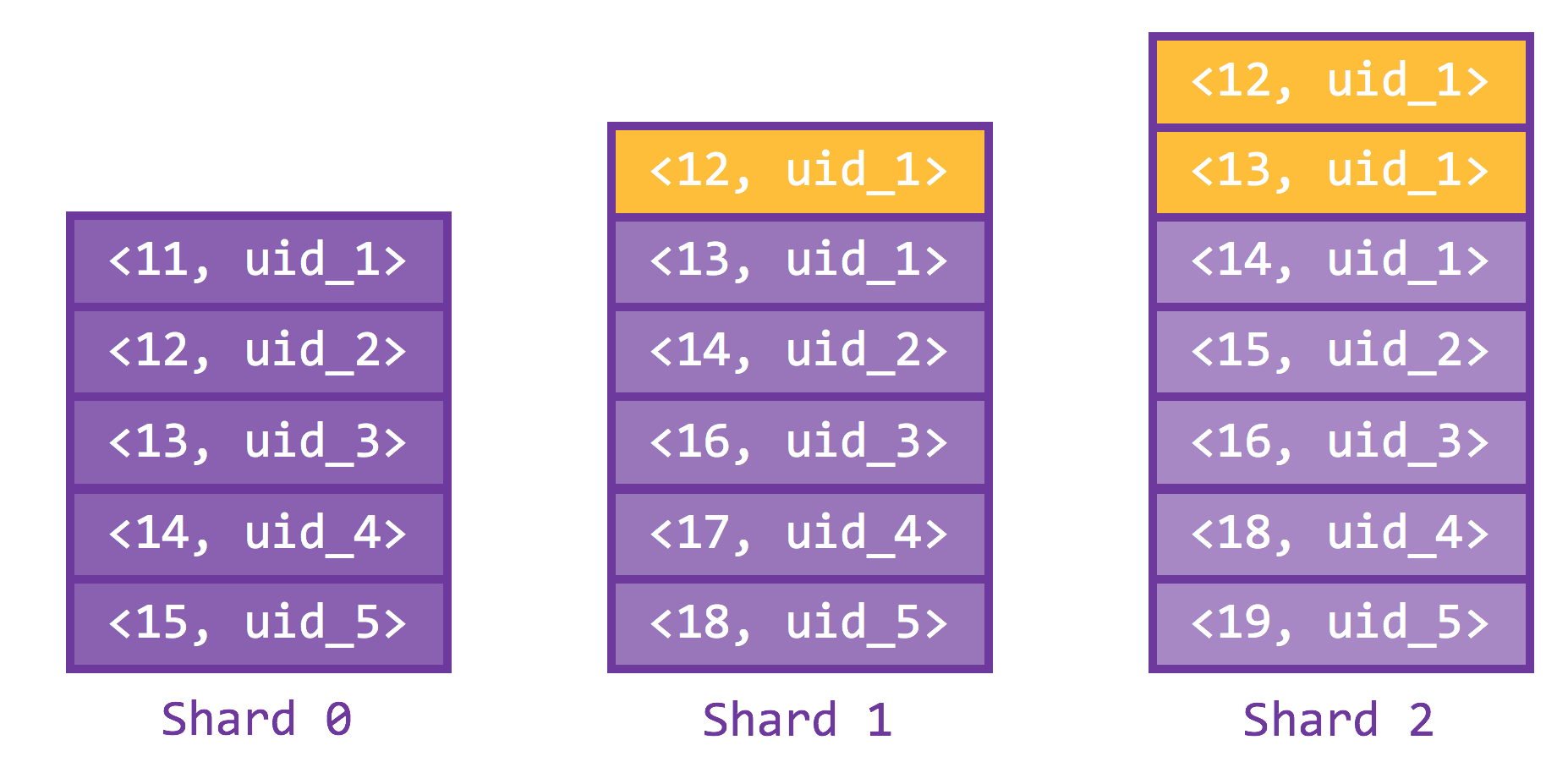
We easily conclude that min has offset 333 on shard 0, 331 on shard 1, and 330 on shard 2 (offsets rounded down since min does not really exist on the other shards). It follows that min on the total order has an offset of 333+331+330 = 994. This is a crucial piece of information, because after an in-memory merging (results from each shard already sorted), we know that the entry 6 rows below min is of offset 1000 on the global order, and limit 5 is just the next 5 immediate neighbors.