Kip’s Warehouse: Building Scalable, Reliable, Consistent Web Application from the Ground Up

I have been working with another three wonderful people on the senior design project, which is a web application of an inventory management system, and the production is up at kipswarehouse.com. The Department of Electrical and Computer Engineering at Duke will be the first customer for our system to manage the items and requests, etc for all ECE labs.
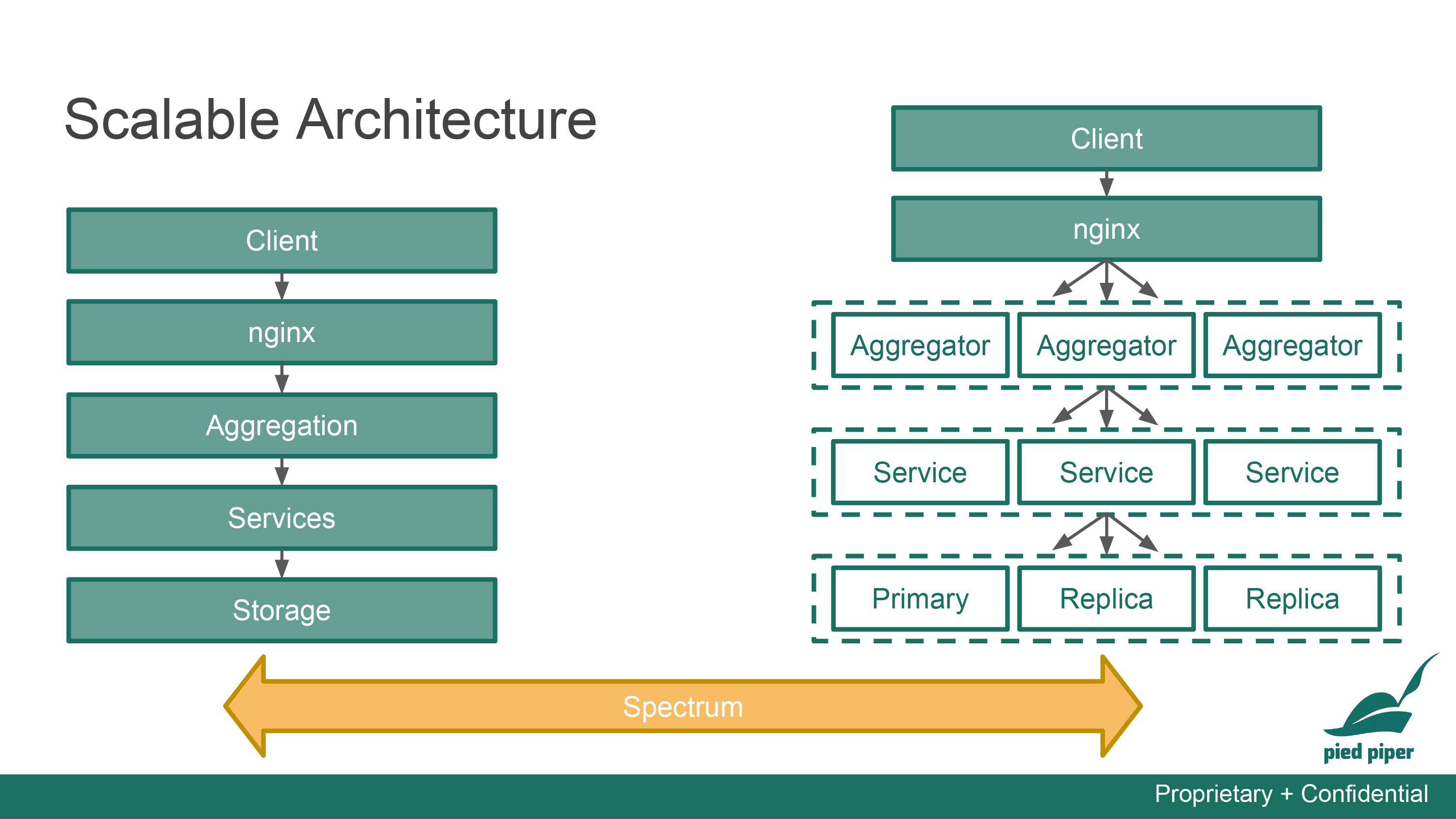
Our tech stack is summarized below.
1
2
3
4
5
6
7
8
9
10
11
12
13
Front-end React + BlueprintJS
Back-end node.js + Express
Web Server nginx
Database MySQL
ORM Sequelize
Backup AWS S3 + Glacier
API json REST
CICD TravisCI
Version Control Github
Code Review Phabricator
VPS DigitalOcean
DNS + CDN CloudFlare
Remote Process Monitor keymetrics
This is a super awesome opportunity. For all my previous internships, I came in with a colossal amount of legacy code that needs to be maintained and carefully updated. This project the very first time where we decide on EVERYTHING in our tech stack, deploy and evolve.
This is also the first node.js application I built. For a semester-long project like this, we prefer fast development and well support. The node engine interprets the script at runtime, so every time we make a change to the server code, no recompilation is required. Our frontend is ReactJS, so it makes sense for our RESTful API to be done over json, and serialization/marshaling/flattening/pickling for RPCs is given for free.
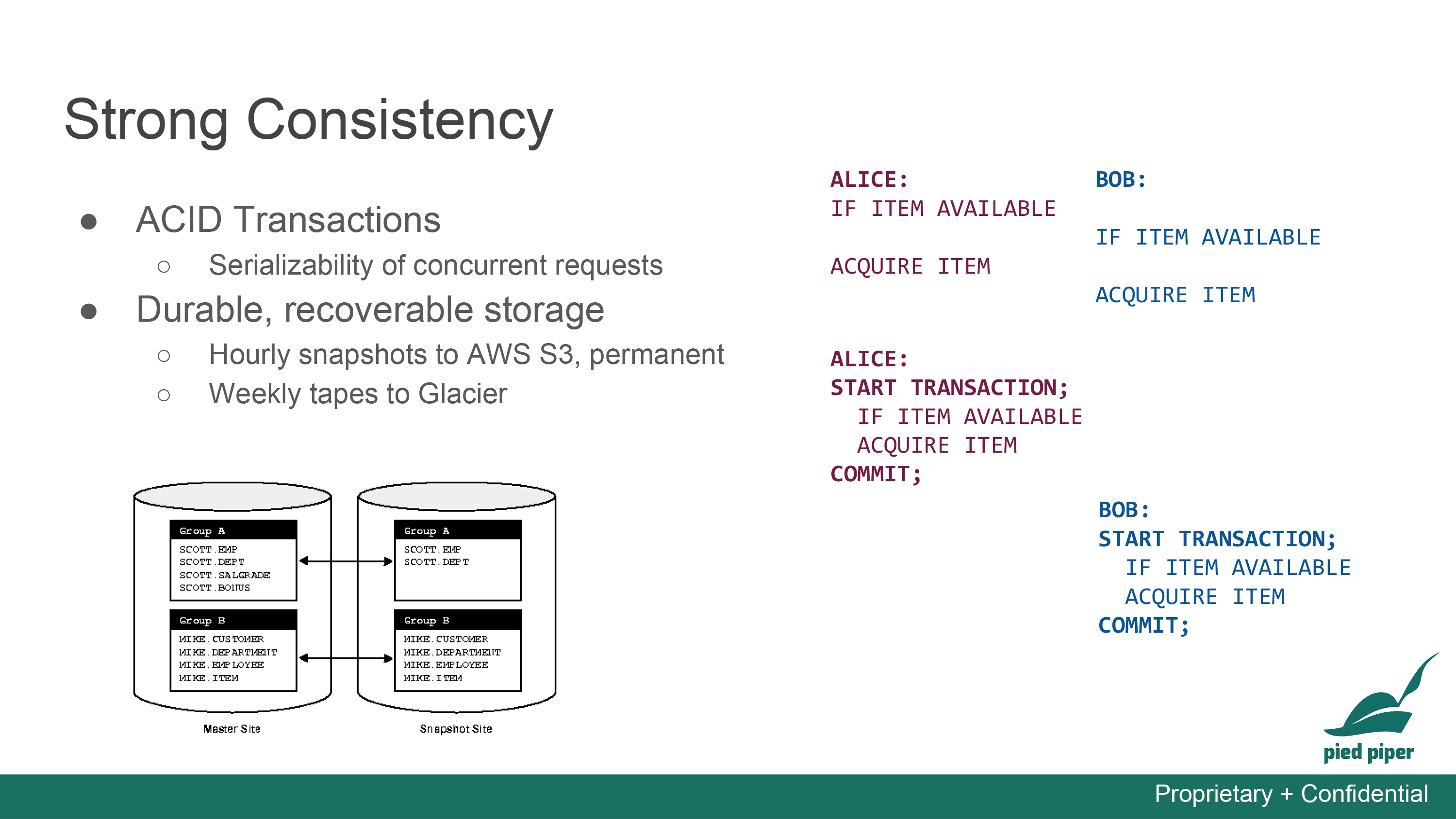
We are also using Sequelize as our ORM to avoid handing writing SQL query ourselves to risk performance. Sequelize by itself has been robust and well documented, but it certainly brings new complexity, if not unnecessary. One notorious case we run into is the transactions on the database. In SQL query, a transaction is a really simple yet powerful abstraction. Start Transaction; Commit; Boom. Two extra lines and you got atomic, consistent, independent, durable records. Sequelize, however, implements it with promises and callbacks. Doing transactions in Sequelize turns into nested callbacks with the transaction object passed all the way into the deepest one. Worse off, if one runs into bugs such as accessing fields on an undefined object, the transaction simply aborts without telling what went wrong in between (which reminds me the dark old days of mysterious segfaults). Normally node.js handles this case well, but now Sequelize masks it and debugging could have been easier.
I attach some slides I used for the presentation of our alpha release. We are definitely hyped about this and will keep y’all updated!
(Oh good lord of Richard Hendricks, please don’t sue us.)