Session Consistency in Replicated Frontend Servers

HTTP provides an abstraction of short connections. Unlike the continuous byte streams in TCP, exchanges between client and server over HTTP starts with a client request and ends with server response, which is meant to be stateless. Sometimes, the server needs more context of the conversation to properly respond, for example, confirmation of user login. Information as such persists throughout the session with the server.
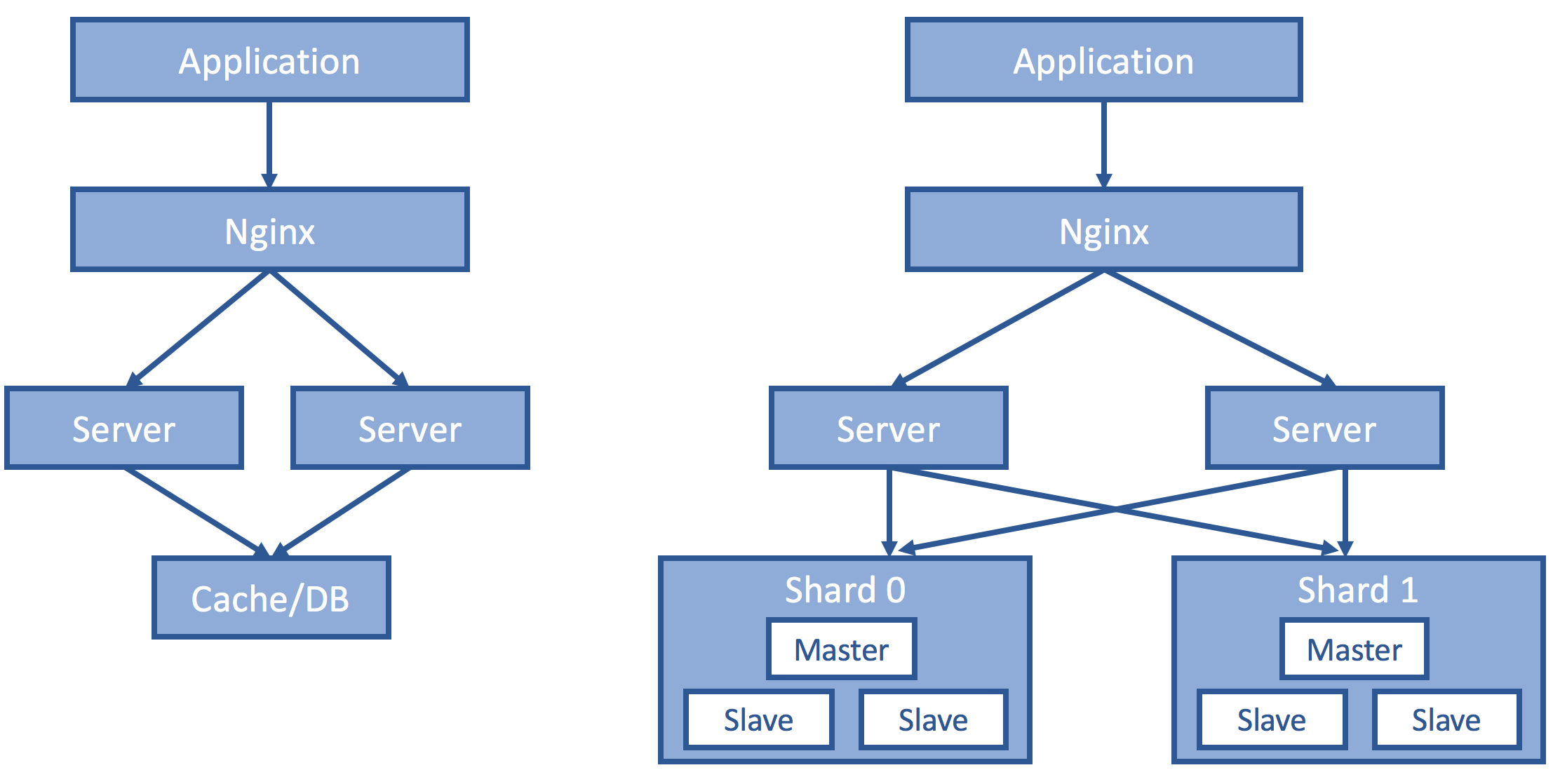
When there is only one instance of the server, that is where the session resides and session consistency follows because of the trivial single-copy semantics.
This design, however, is by no means scalable or highly available. Oftentimes, such frontend servers are identically geo-replicated and routed with a reverse proxy. The challenge is how to maintain a session even if subsequent client requests hit some different server. Several solutions are presented here and the pros and cons discussed.
Server synchronization: gossip/epidemic/anti-entropy
If the session is synchronized among all servers, then it does not matter which one the client hits. We do so by having servers exchange all session information.
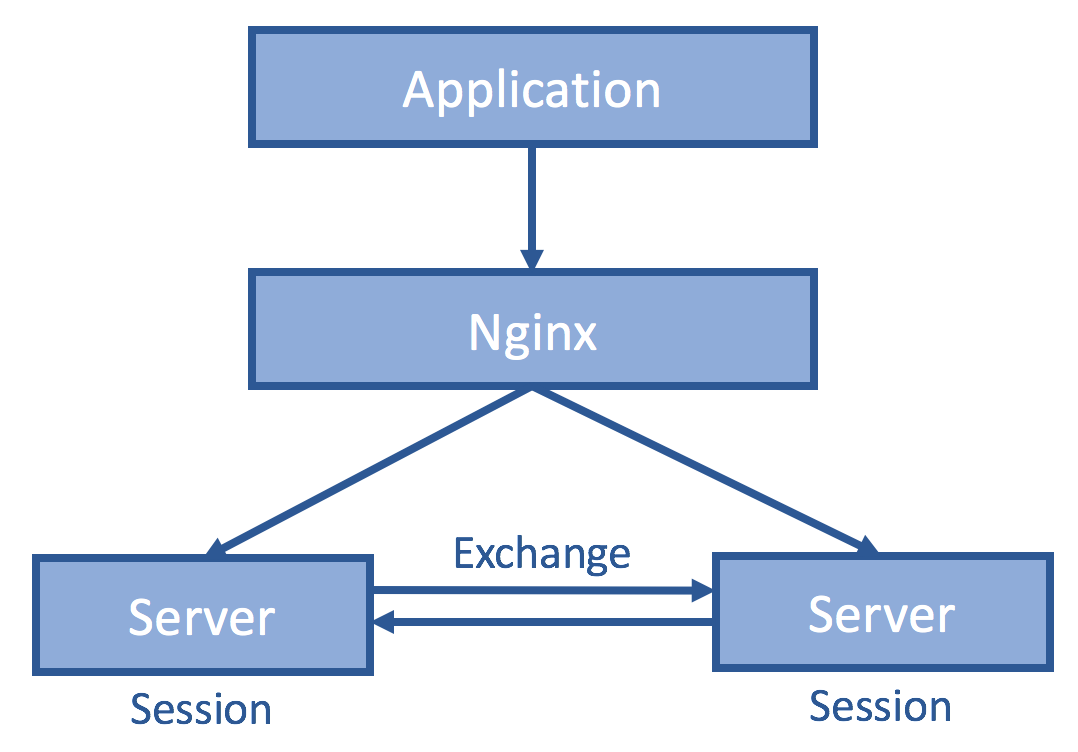
It is nice that such a change affects no application code. However, synchronous server exchanges impose additional delays to ensure all other replica servers have received such session info, and worse, then entire endpoint becomes irresponsive during network partition among servers. Asynchronous server exchanges, on the other hand, provide only weak/eventual consistency, so in our example, users might be asked to log in again even after they have done so. Lastly, such a scheme does not scale as the number of exchange messages grows exponentially with the number of servers.
Consistent hashing
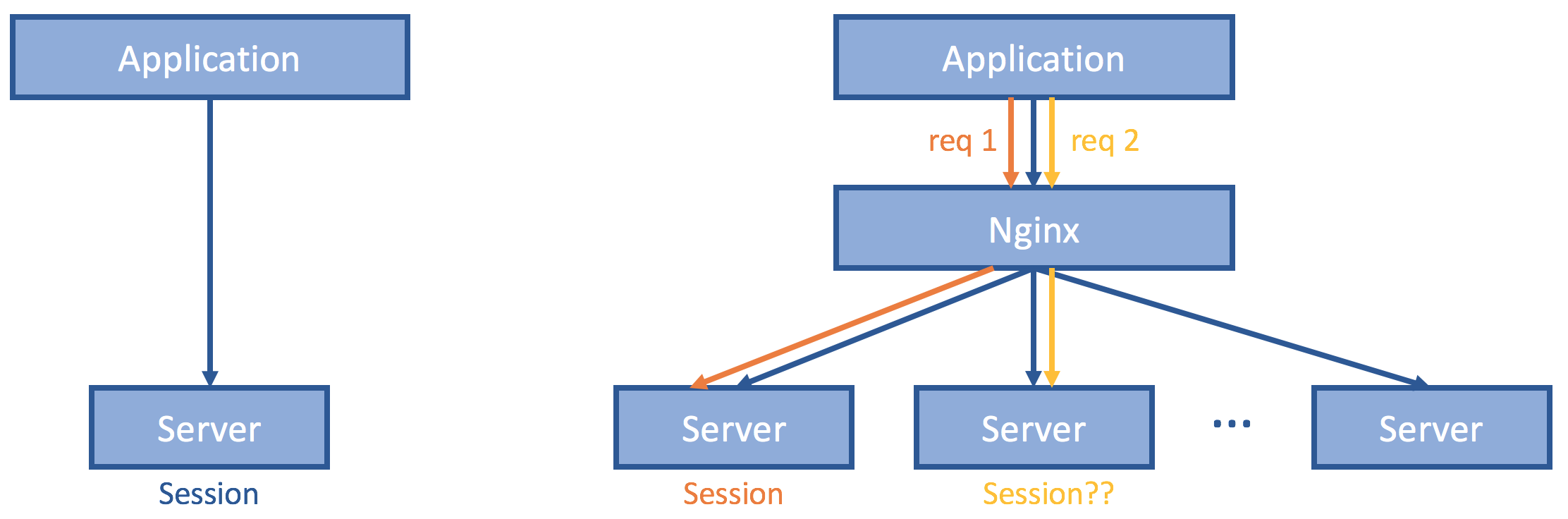
If we ensure that requests from the same client always reach to the same server, then we do not have to deal with session replication and consistency anymore. Instead of doing randomization or round robin, perhaps the reverse proxy could be based on IP address (Level 4 routing) or business logic property such as user_id, order_id, item_id, etc (Level 7 routing).
This is nice since we only need to change the Nginx configuration and application/server code remains intact. Loads at the servers are also balanced, assuming good hashing scheme. Also scalable with more server instances. However, this does not solve the high availability part, since whenever the server fails or partition happens, clients are unable to talk to the original server and must be remapped to a different server and log in again. Upon replica set resizing, redistribution of session information must happen the same client might be hashed to the newly added servers.
Client-side storage
To manage the session information on the client side, one might take advantage of the browser cookies, which relieves bandwidth and storage burden from servers. However, it might be subjected to illegal mutation, leaking, and other security threats. The session is also limited by cookie size.
Server-side durable storage
This is, in my opinion, the best solution. We keep the session information in our backend storage, which makes the frontend server truly identical and stateless. You may ask what if the storage fails. That is an excellent question, and the state-of-the-art answer would be sharding, replication and high-power consensus (paxos, raft, viewstamp). It makes more sense to consolidate these properties as a service and build other services on top of that (Chubby, Zookeeper, BigTable).