Service-Oriented Architecture: Why did Microservices Catch On

- All teams will henceforth expose their data and functionality through service interfaces.
- There will be no other form of inter-process communication (IPC) allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever.
- The only communication allowed is via service interface calls over the network.
- Anyone who doesn’t do this will be fired. Thank you; have a nice day!
– Jeff Bezo, Amazon CEO
You may have been wondering why in the world would anybody prefer the extra layer of abstraction (the service tier) instead of just doing things the old way.
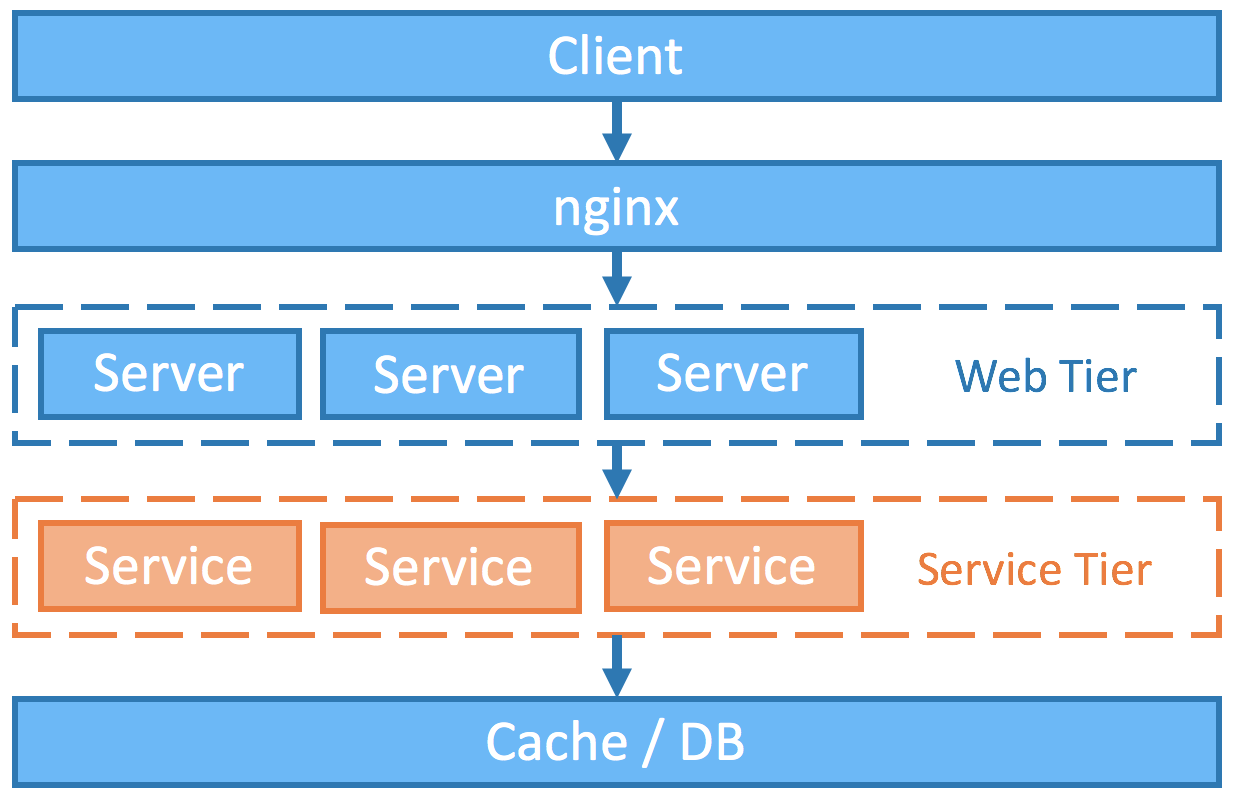
Microservices are really just a more concrete and modern interpretation of service-oriented architectures (SOA). It goes one step further by taking on the UNIX design philosophy where each service/command does only one thing and does it well. To help understand the advantages of SOA, I have listed out some potential problems that one could encounter without the service tier and I will explain how SOA has cracked them.
Duplicated code
Consider the following hierarchy where all three types of requests do queries on user data.
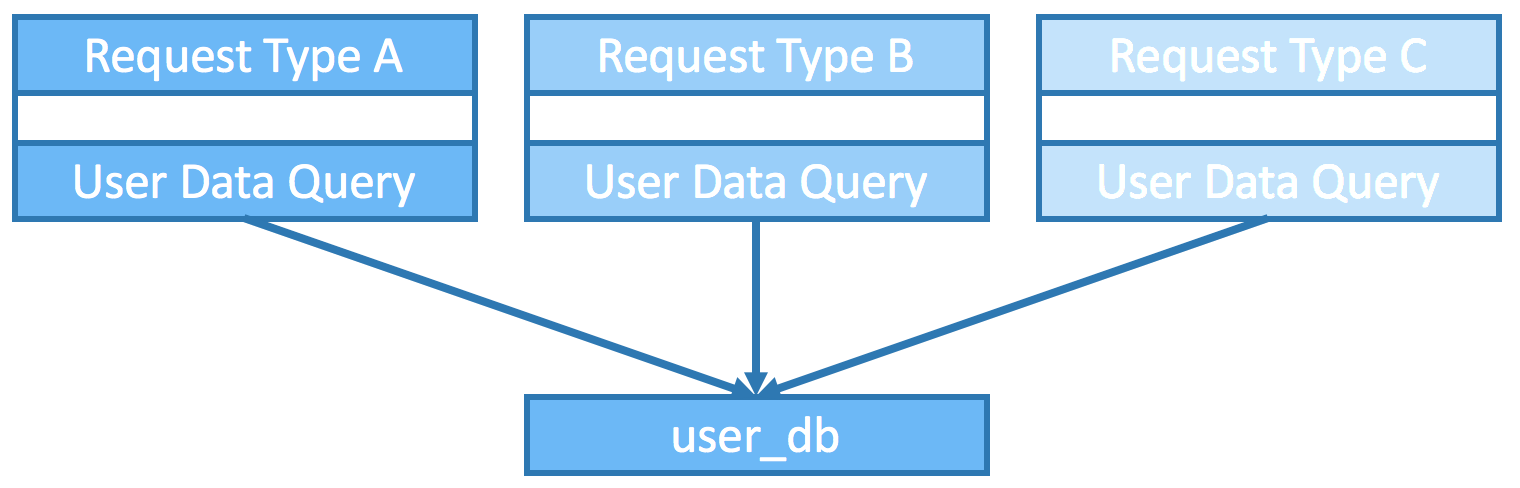
Without the service tier, if requests are handled by different servers, then each of the servers need to implement the SQL query individually, which essentially creates duplicated code.
Spread of Complexity
As concurrency bulks up, database queries become bottlenecks. Cache is then introduced to the to hierarchy to mitigate query volumes that actually hit DB. Without a unified service tier for user_db queries, upper layers must upgrade to deal with the new cache layer directly. This new directly-exposed request-unrelated complexity forces all servers to upgrade. Imagine doing this over and over as your business goes. Did I mention you also need to keep track of all different places that are impacted every time you make a new change?
Reused but Coupled Library
SOA is not the only solution to the two problems aforementioned. Extracting common actions to a library, say user.so, is mostly the first solution found. Single point of update, hidden implementation, unified interface, great. But doing so introduces new problems – version maintenance and coupling of code. If server pipeline A handling request type A upgrades user.so from version 1 to version 2, other server pipelines are forced to upgrade to be compatible with the new version of user.so, the comeback of problem 2. Or, we could retain a different version of user.so based on the pipeline, but then problem 1 arises.
Performance Impact by Other Server Pipelines
Each server executes SQL queries on its own. If server A does a full scan on user_db and takes DB CPU to 100% to usage, it essentially blocks all other servers from making progress.
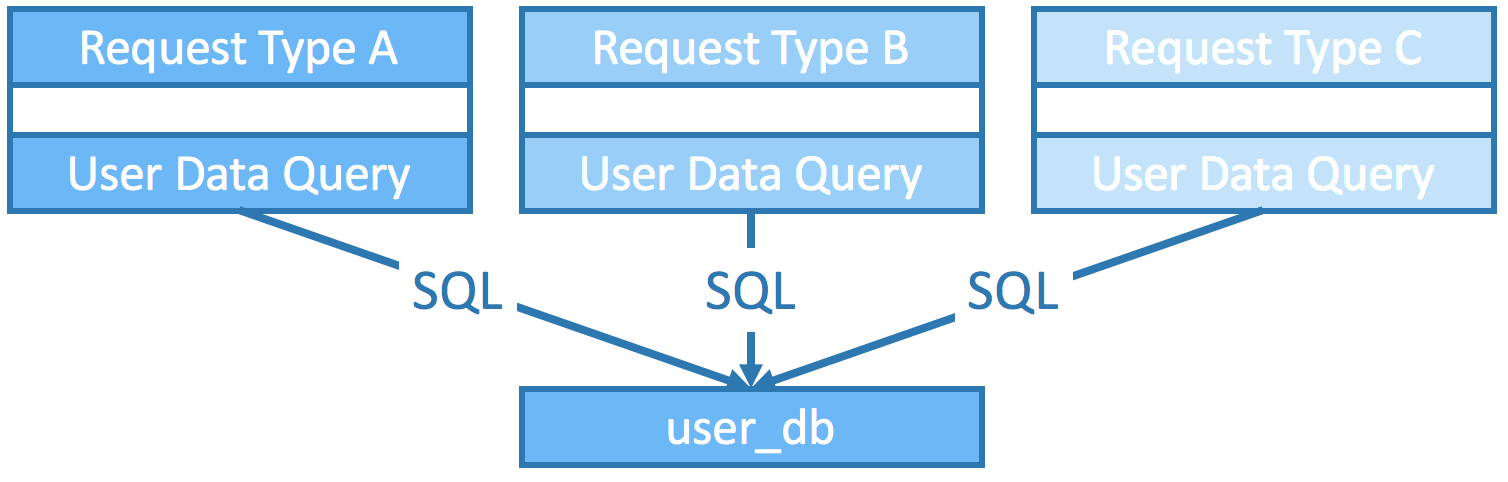
How SOA solves them:
- Single point of change. Fix one bug in service tier you fix them all.
- Unified abstraction for upper layers hides implementation details. Changes such as new cache, extract db, split table preserves the interface exposed to clients, who no longer needs to keep on updating along with the service.
- With the new service tier
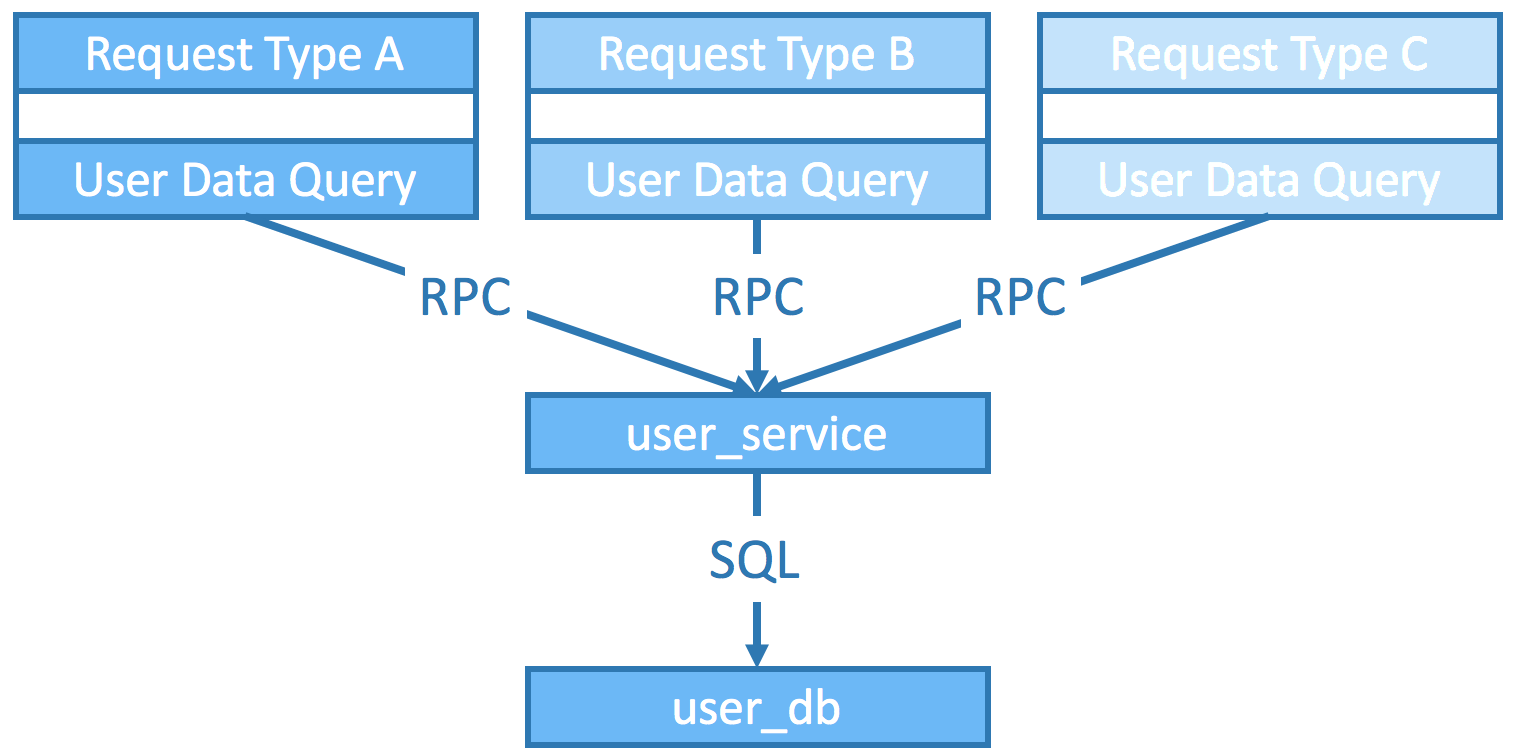
Now the user_service could mitigate/schedule queries to DB and no single server could have it all, which preserves the minimum performance spec.
- Easy to use. Before you need crazy linking and binding for communication, if not serialization, reliable transmit, background execution, etc. Now it is all RPC which appears no different from invoking local procedures.