Reliable & Consistent Service: Linearizable RPC and Replicated State Machine
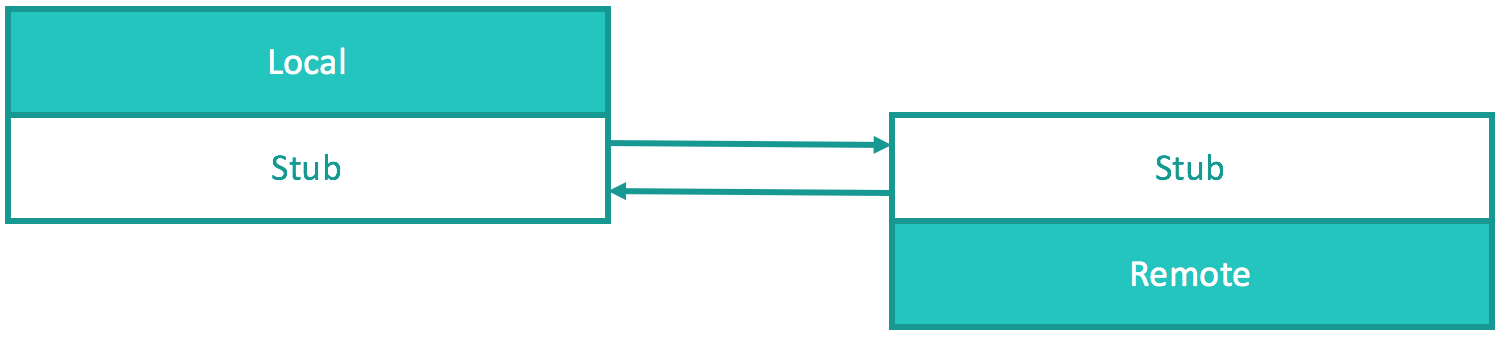
Remote Procedure Call (RPC) is a canonical structuring paradigm for client-server/request-response services.
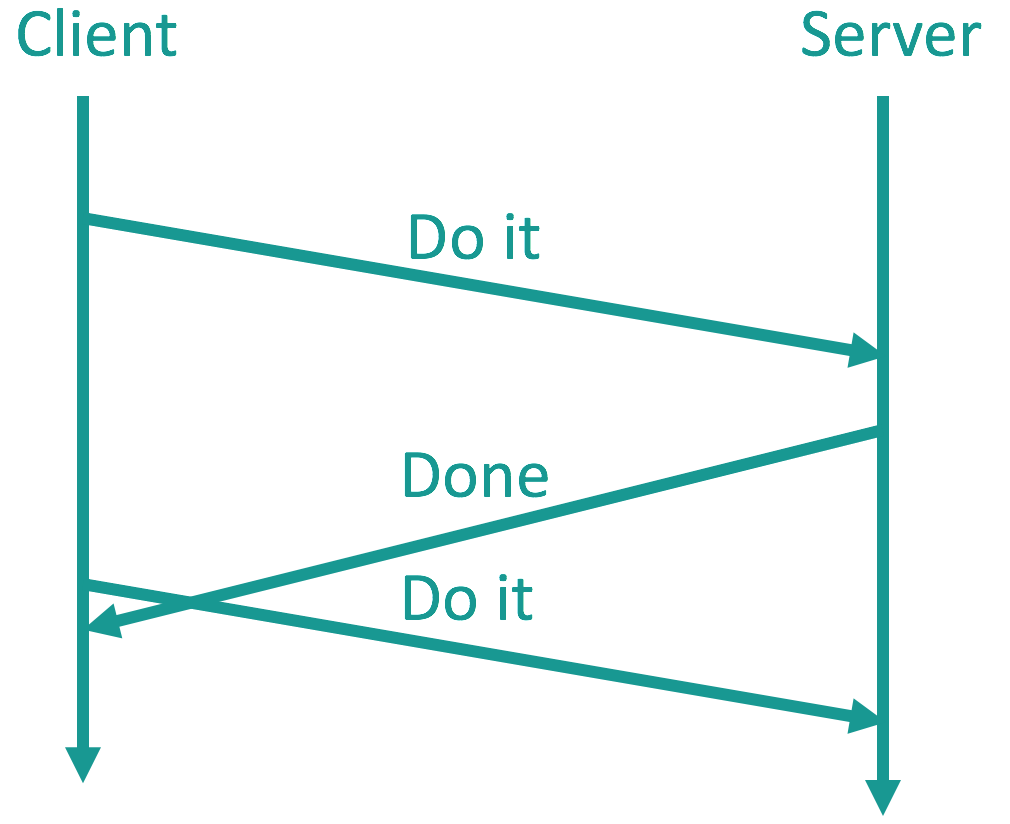
This simplified diagram overlooks the challenges we face such as unreliable networks and remote server crash and recovery. In the famous Birrell/Nelson paper, at-most-once semantics was proposed that request is resent upon timeout so it eventually does reach the server, and that server is stateless so it restarts when failed and continues service probably retransmitted request (a failed server is a slow server).
But then a request might be retransmitted right before the response arrives so that the operation might be executed twice.
In the 80s, people believe that requests are essentially read and write, both of which are idempotent, meaning executing them twice will not change the response, so at-least-once semantics are fine. For a long time, we thought at-least-once semantics + idempotent operations = linearizable RPC, but it turns out it is not necessarily true. Consider the following example. The very last read should return 3 in a linearizable system. The takeaway is we need exactly-once semantics.
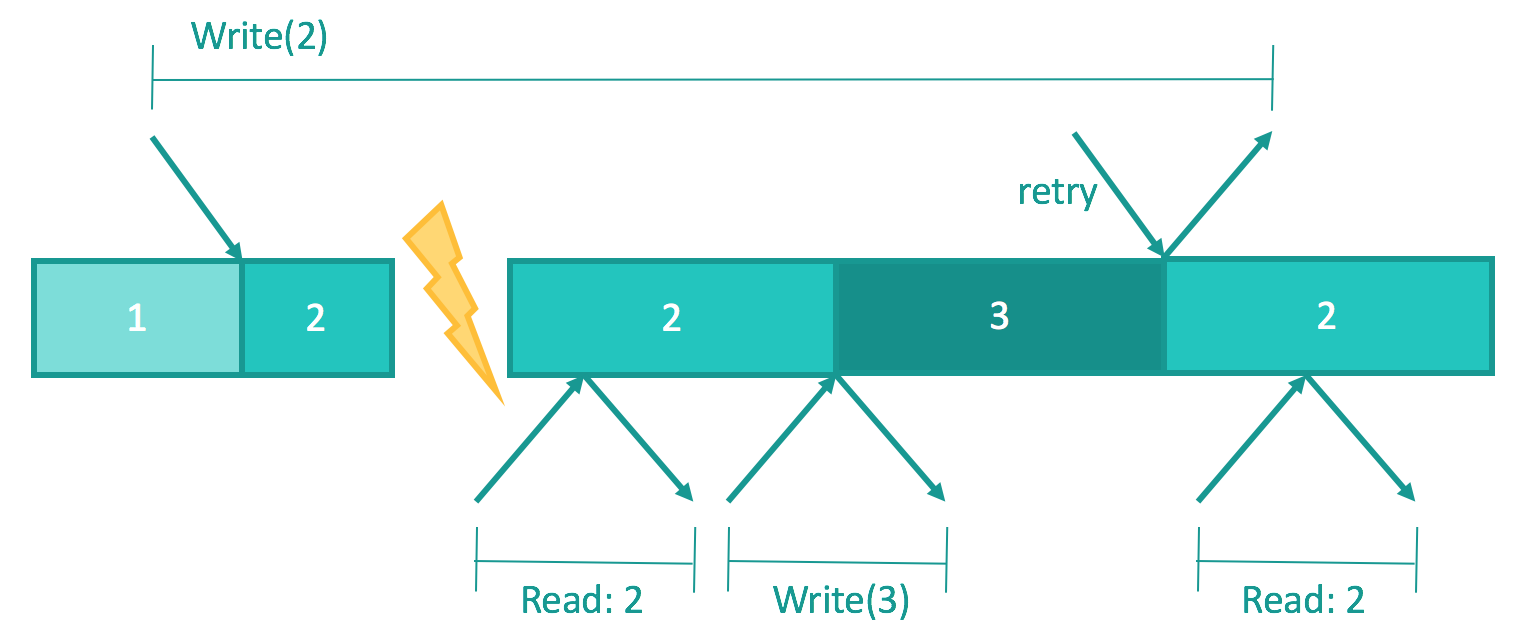
Reply cache has come to rescue. Each RPC is tagged with an id and its return value is put in the reply cache such that when the retransmitted RPC arrives, the server does not re-execute and return the value in cache immediately. The cache entry is evicted when the client ACKs. Using a reply cache achieves at-most-once semantics, which combined with retransmission achieves exactly-once semantics.
But what about failovers? When an instance of the server fails, all loads are shifted to other servers. To get consistent results requires the reply cache to be durable, which means each operation replicated across the entire server grid. This is why linearizability is so important. A concurrent implementation is correct if its behavior is equivalent to some serial order. Each server could be viewed as a state machine and with a sequence (linearized) of applied actions, its final state is deterministic and could be replicated. Paxos, Viewstamped Replication, Raft are all consensus algorithms for replication.
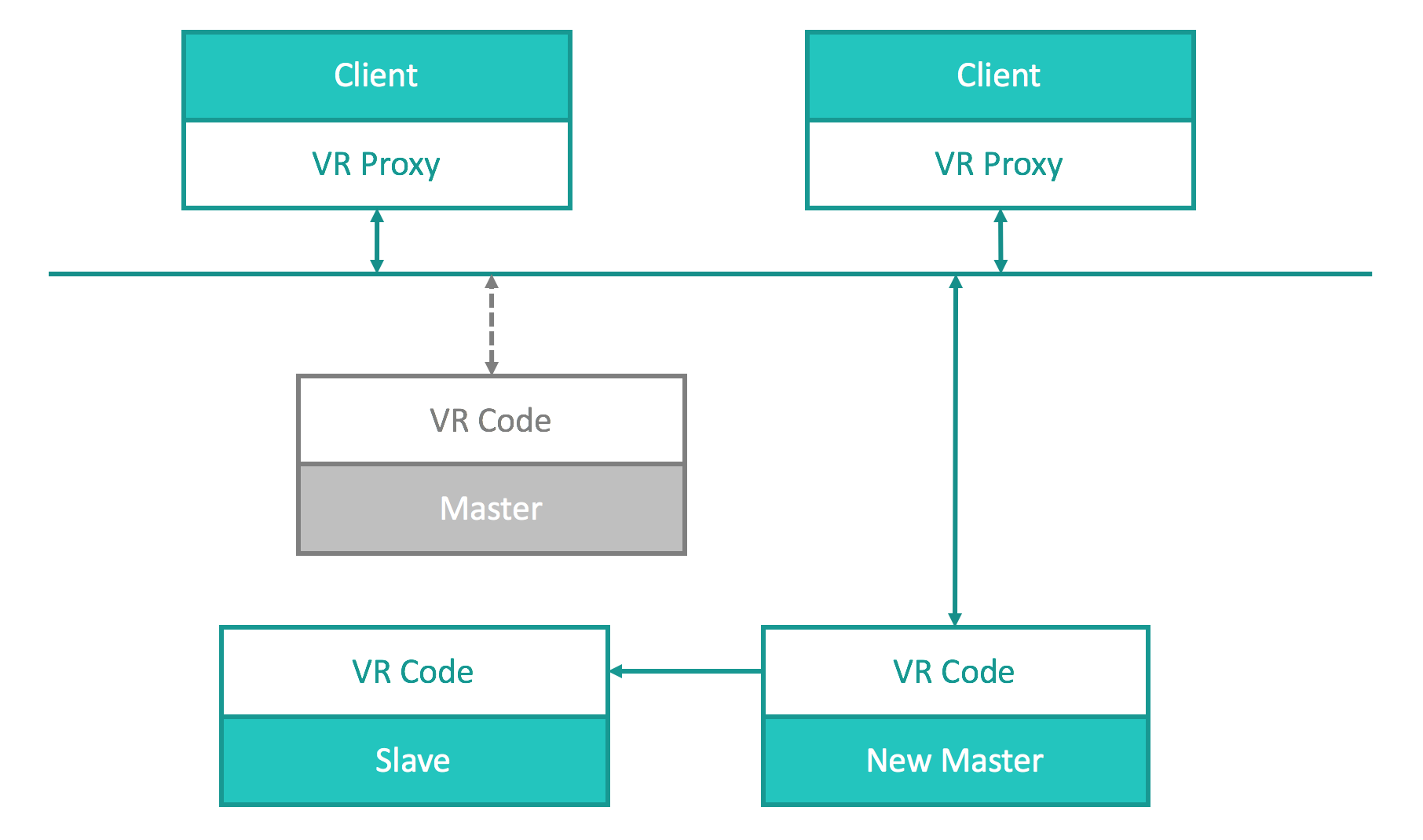
The one last twist is that upon failovers, the client needs to keep track of the new elected master/leader and send requests to her. Of course, the client application is not the one to do such bookkeeping.
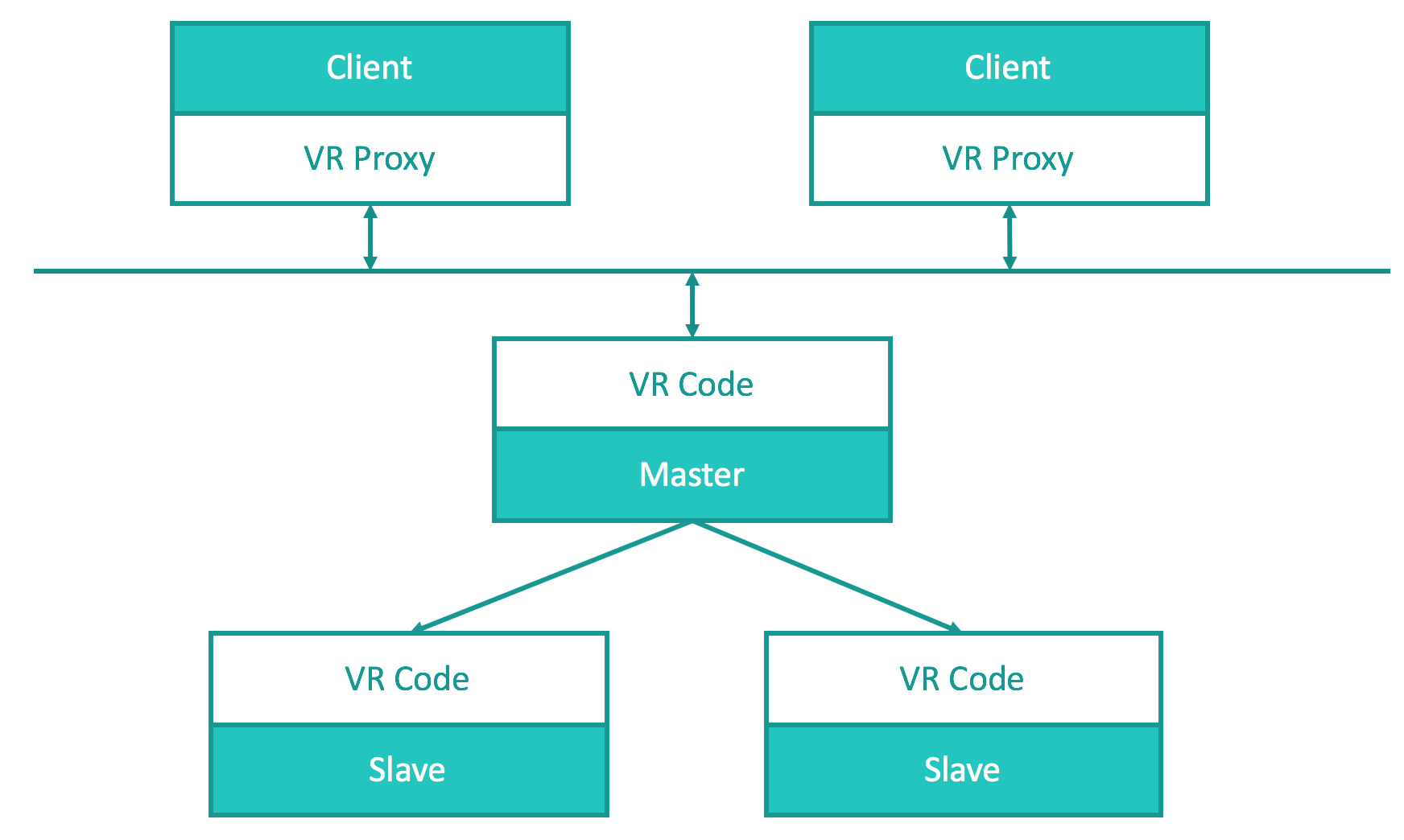
Take Viewstamped Replication for example. VR Proxy on the client side keeps track of the current master. On the server side, it is the VR code that manages replication, election, etc. It is therefore independent of the underlying server code and could be reused readily.