Git as Version Vector
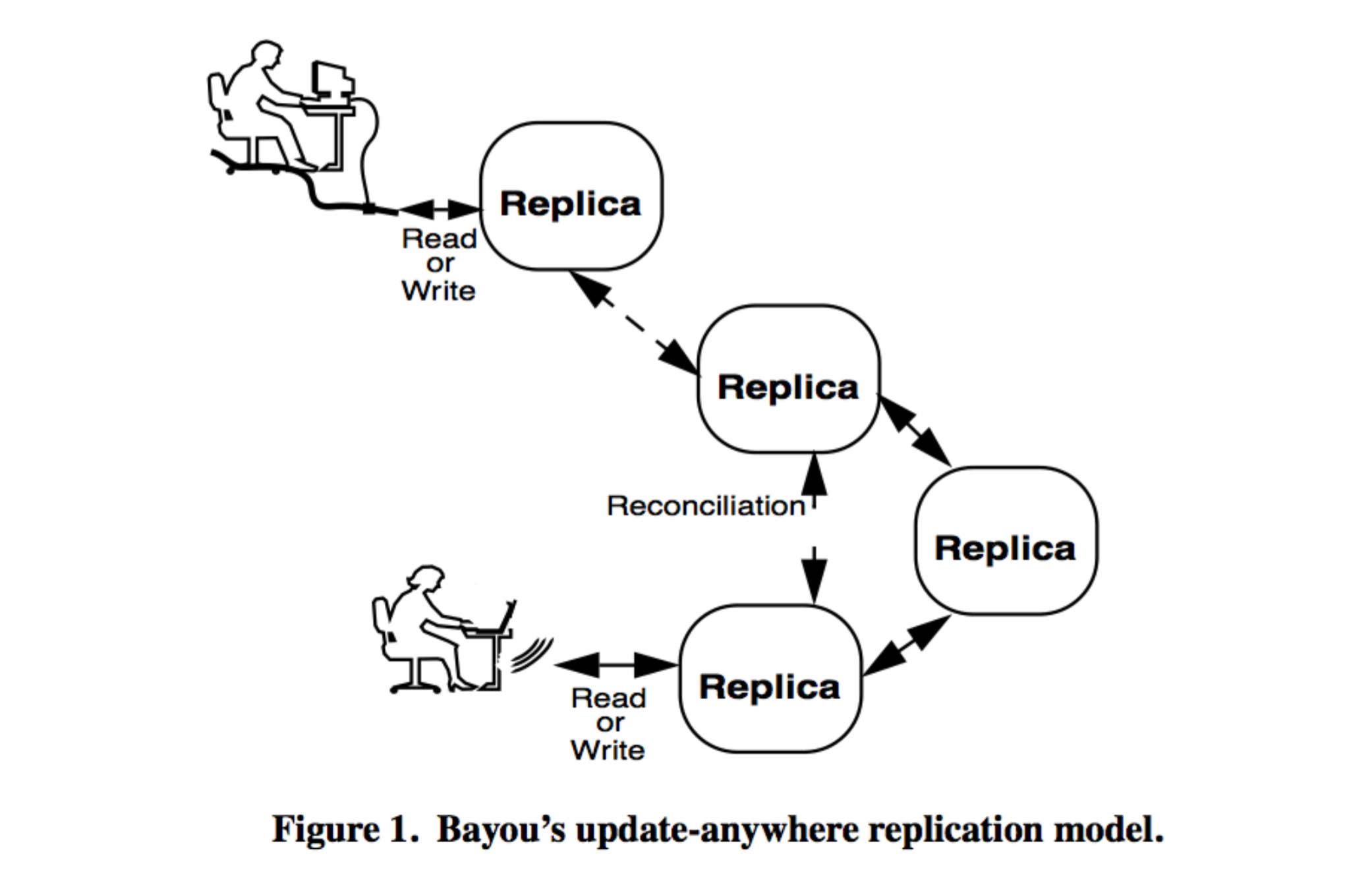
Git is one of the most widely used version control systems. Traditionally, a repository on git is considered as a complete history of the entire project in the form of chains of blocks. Each block is a commit, and one could create a version branching from any point throughout the chain.
Alternatively, one may view git as a highly available system that implements version vectors. It is highly available in that whenever you push to your local repo git never rejects you, but of course that local update is tentative until it is appended or merged with master. The interesting aspect of git arises when you branch off master and work on a feature branch, while others at the same time could do exactly the same. This is a concurrent update.
We are speaking of concurrency in a rather strict sense. Consider the following example.
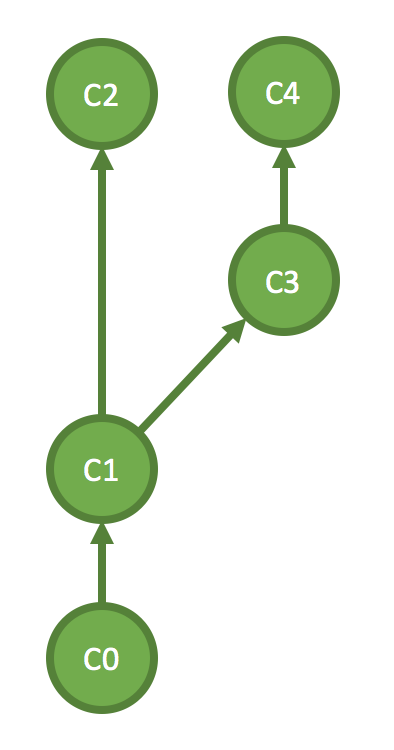
When C3 branches off C1, C3 must have seen C1 as well as C0, so we say C0 causally precedes C1, and C1 causally precedes C3. Causality here is defined as a happened-before relationship, where C0 might not necessarily cause C1 but it could. However, when someone else appends C2 onto C1, he or she has not seen C3 or C4, and the person working on C3 and C4 has not seen C2, such that C4 does not causally precede C2 and C2 does not causally precede C4. Therefore, C2 and C4 are concurrent.
Remember that git ensures a total order of updates/commits as seen by all the participants, which means concurrent modification as such must eventually be serialized as either C2 precedes C3 and then C4, or C3, C4 and then C2. Which order to choose is rather arbitrary but what matters is that once a causal order is chosen, the rest of all participants must agree and observe such ordering. Concurrent updates might be conflicting, and that is why the git merging procedure requires user involvement to resolve merge conflicts.
But how does git know whether two updates are concurrent? Version vectors. It all started with the hall of fame paper Time, clocks, and the ordering of events by Leslie Lamport, who defined a total causal order using the logical clock. The logical clock (LC) is just a monotonically increasing counter and each branch has its own logical clock. Each commit on branch i is then stamped with <LC_i, i> and a causal order could be defined as from lower LC to higher LC and break the tie using i.
Notice that there could multiple causal orders given a set of events, and the order derived from LC while preserving causality imposes an unnecessary ordering constraint on concurrent events, and worse, using just logically clock is insufficient to tell whether two events are concurrent. Users might desire a different order after all.
So we need a vector clock, which is a vector whose element at index i is the logical clocks of branch i. Now we know update u causally precedes update v if VC(u) dominates VC(v), and such domination is true if each logical clock in VC(u) is greater than or equal to that in VC(v) at the same index. Therefore, if neither vector clock dominates the other, then we conclude that the two updates are concurrent, which is where a merging procedure is needed.