System Design Interview: Scaling Single Server

Table of Contents
Imagine your app is doing tremendously well with growing traffics. If there is a single server for your app, and the server is approaching its capacity, how would you scale to handle the load?
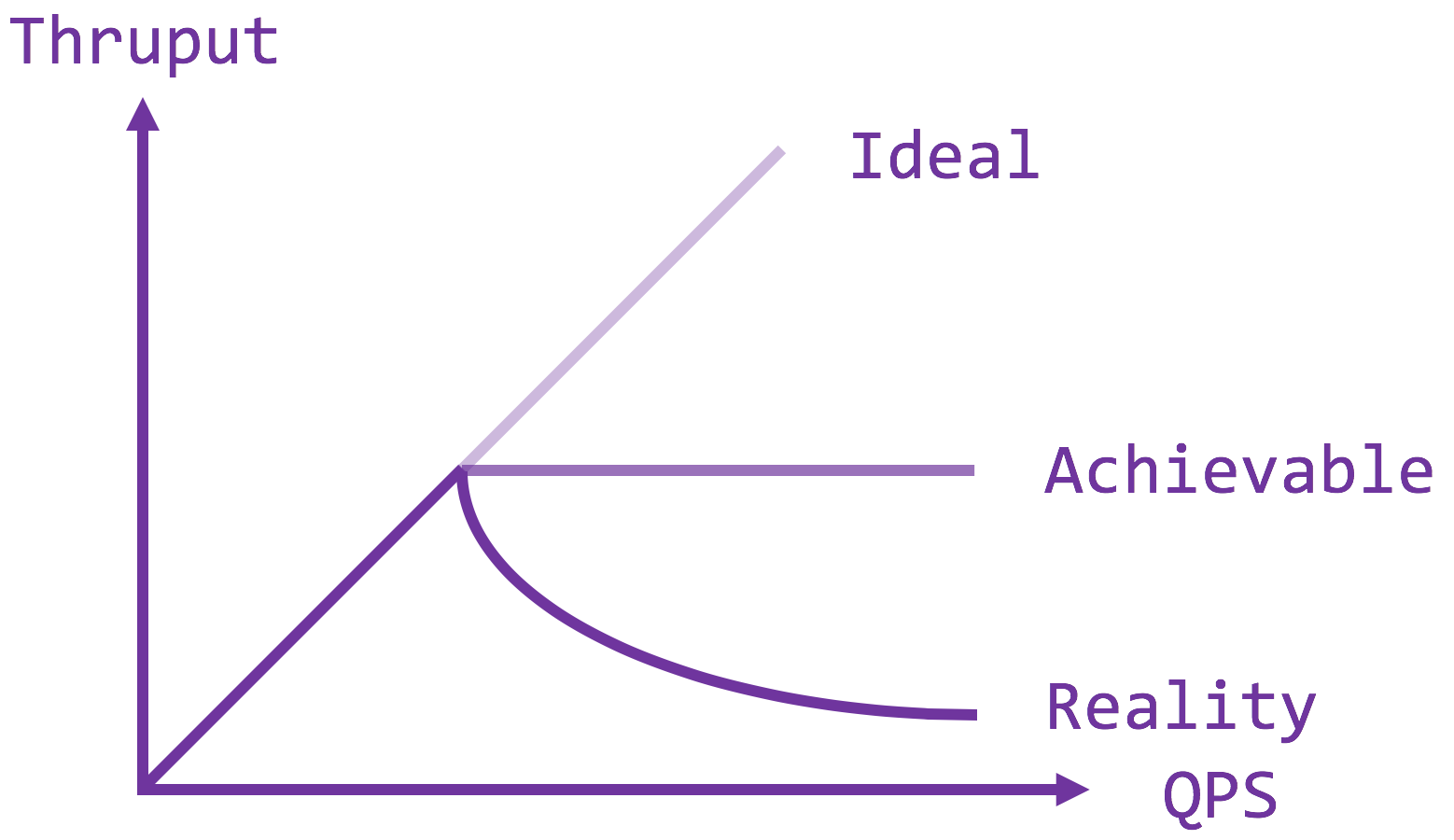
A slight digression to why it is bad if the server loads go beyond the saturation point. Ideally, we hope that the server throughput increases as its loads, which is only true up to a certain point due to physical limitation – RAM, CPUs, IO, etc. Beyond that, one could manage to sustain the same level of throughput if they know what they are doing (more blogs on this to come), but a more common scenario would be an exponential decrease in throughput due to receiver livelock where network packets are handled as interrupts at a higher priority than the server process. At high arrival rate, the CPU is constantly preempted to handle the incoming packets, only to drop them because of full buffer / queue, hence the server process hardly ever gets run to deplete the queue. The moral of the story is to get close to but not over the saturation point for reasonable latency and throughput.
Back to the starting issue. What if the traffic going beyond the saturation point? The simplest answer would be to scale up / vertically, as in running your server process on a much more powerful machine, perhaps more RAM for caching and more cores for throughputs. But there is a limit on the state-of-the-art configuration – there are only so many cores on a single chip or so much RAM that the motherboard supports. Hence, the server must scale out / horizontally, be able to do more when it needs more.
Stateless Frontend / Edge / API Servers
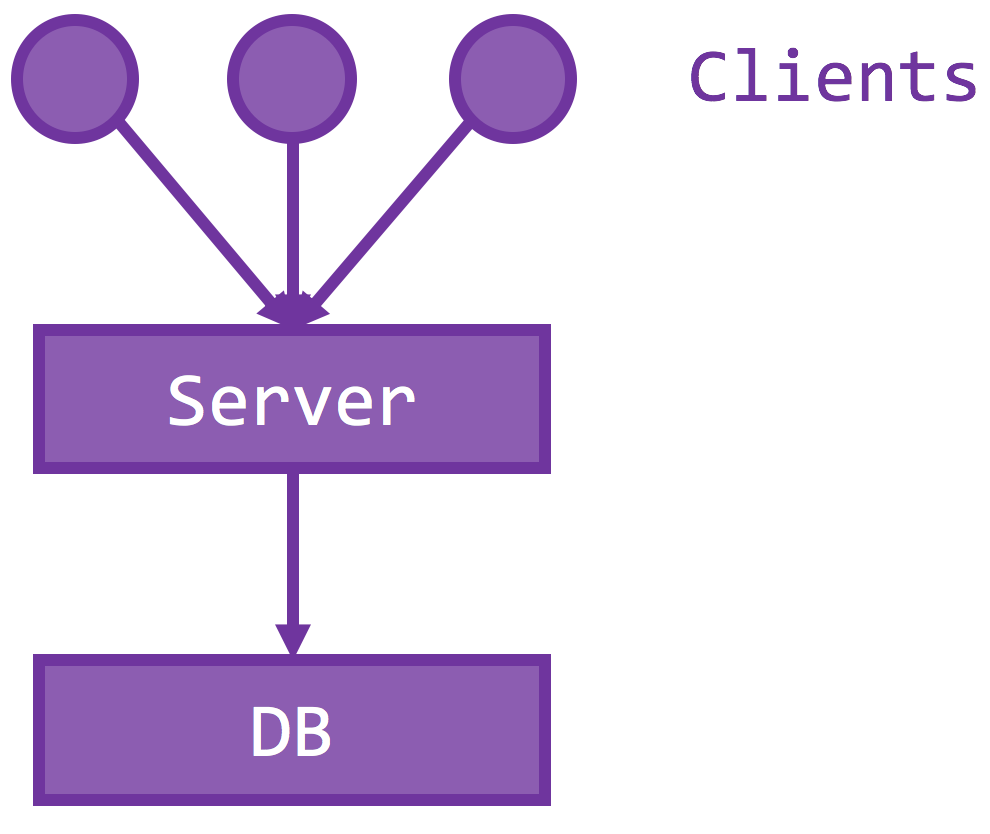
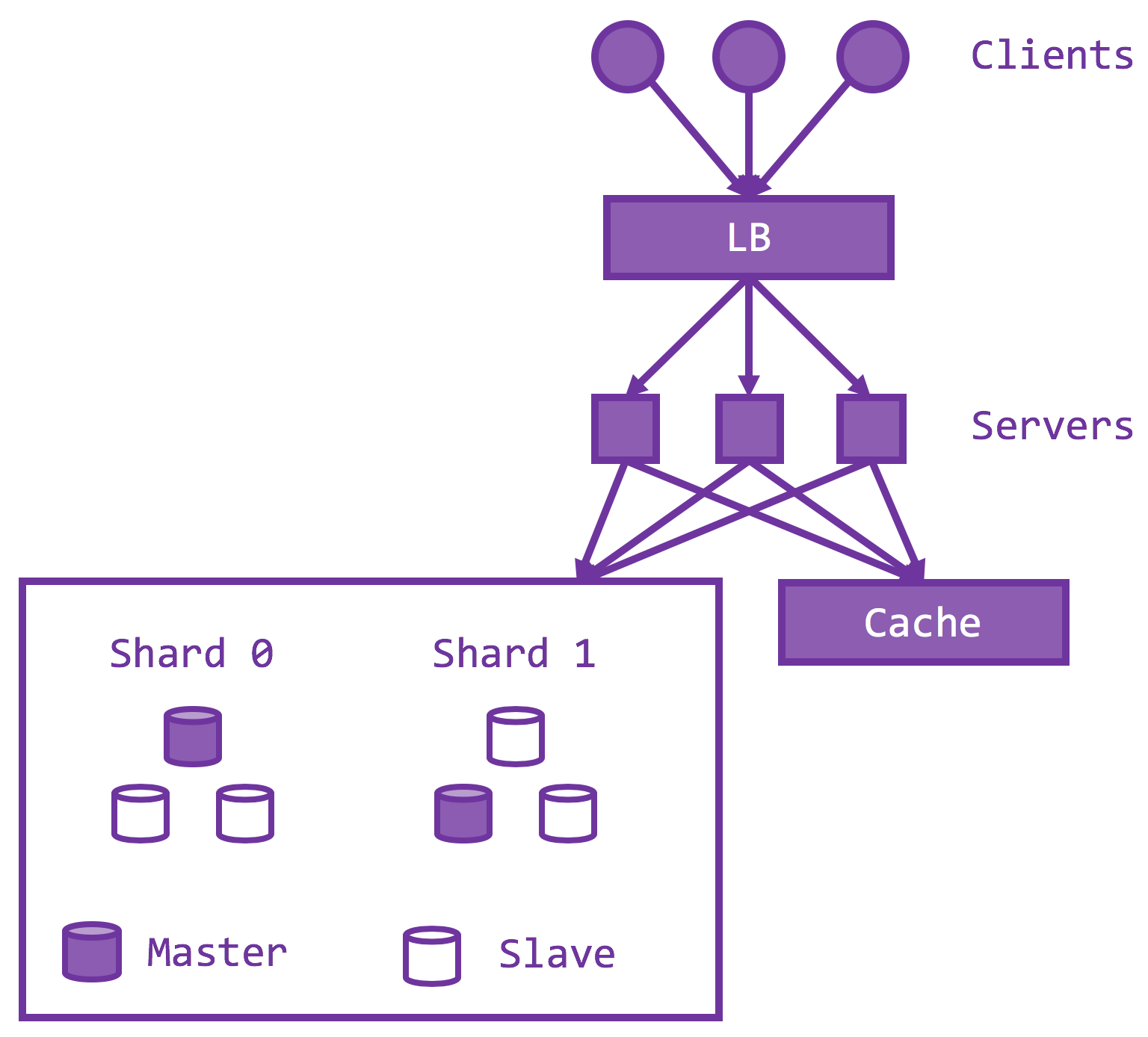
To do so, the server has to be stateless, or all states must be externalized to a durable, secondary storage. A stateless server is beneficial because crash recovery is easy – just restart and connect to the database – and to scale out means to provision another identical instance connected to the same storage. Then you essentially doubled the throughput, going from one server instance to two, assuming the storage has yet to reach its capacity. The new server instance could (should) be deployed at a different geographic location so their faults are isolated. If one of your data centers is out of power, the rest of your servers could pick up the load. Usually, all of the servers sit behind a load balancer / reverse proxy, so that a single IP address is exposed but server membership could also be easily managed. Doing so also helps achieve even distribution of loads on the active set, with your favorite load balancing scheme – L4, L7, round robin, random, shortest queue, etc.
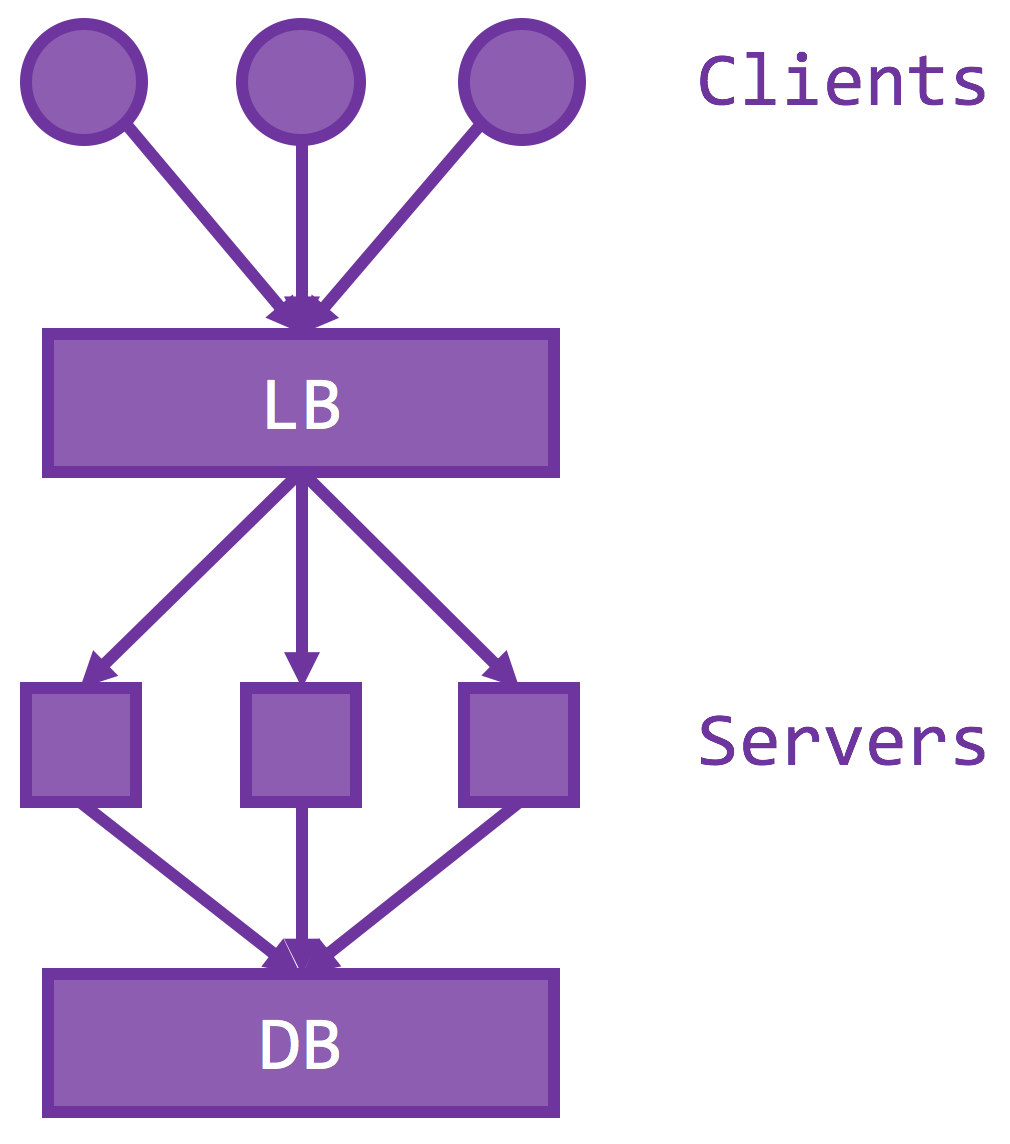
As we add more servers, the storage becomes the bottleneck. There are essentially two ways to scale the storage – split the storage into multiple shards / chunks / partitions so they can serve at the same time (and thus throughput multiplies) and a hot cache to intercept most of the loads to storage.
Memory Cache Cluster
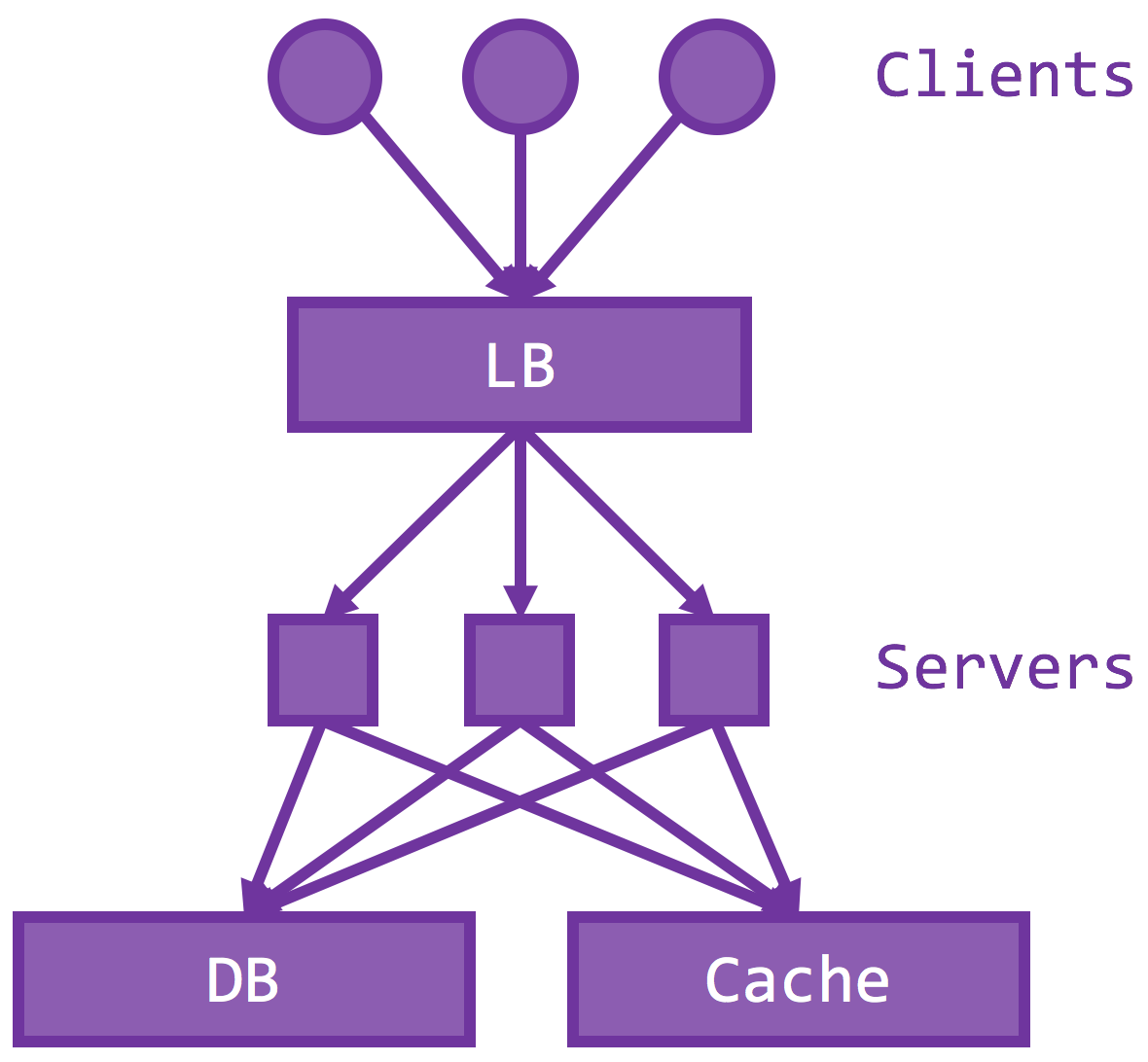
The number one rule of any architecture design is to make common cases fast. An epitome of such design philosophy, memory caches (memcached, redis) are another downstream service that caches frequently accessed server responses only in memory. No persistency means no disk I/O and hence much lower latency and higher throughput. Prominent use cases include celebrity tweets or trending YouTude videos, where 10% of your content attracts 90% of the traffic.
It is okay to miss. It is okay to fail. Those are two import points people often missed about memory caches. Cache is by definition not the storage layer. If the cache missed, the client could always fall back to DB. Indeed, one has to mind the cascading failure where if the cache fails entirely, all traffic hits and essentially kills the persistent storage, but building a replicating consensus quorum on top of memory caches is the anti-pattern of caches. Doing so introduces additional round trips in delay by the farthest replica. The better approach should be a cluster of memory caches, sharded but not replicated. If any of those failed, traffic on those partition keys hits the DB but should be miniscule on the grand scale. In the meantime, erect another instance of memory cache elsewhere and when it is ready, routes traffic on the previous cache there and none of these operations need to be synchronous – if the cache fails, hit DB; if the cache is cold / just up, hit DB and write through; if the cache is up but some client has yet to discover, hit DB. Key to success is fine-grained partition space.
Sharding
Each piece of data is assigned to a particular shard using a partition key, which is usually the primary key. Such assignment has to deterministic, so that the data can be retrieved / queried, a task not as trivial as it seems. Imagine the strawman example with N shards to start with and an assignment function partitionKey mod N. Suppose such set up is falling behind the loads. Adding any additional shards changes N and thus breaks the assignment scheme, since the same partition key is likely to be mapped to a different shard using the mod function given that the total number of shards have changed. The assignment task is exactly like hashing where a key is mapped to a bucket. Worse, to fix this mismatch, the entire storage has to reshuffled so a key to put to the right shard, and you have to do this for every expansion. Our goal is to devise a consistent hashing scheme with minimum redistribution. There is an awesome paper on this and I will not bore you with the details, but a 1,000-foot view is the following.
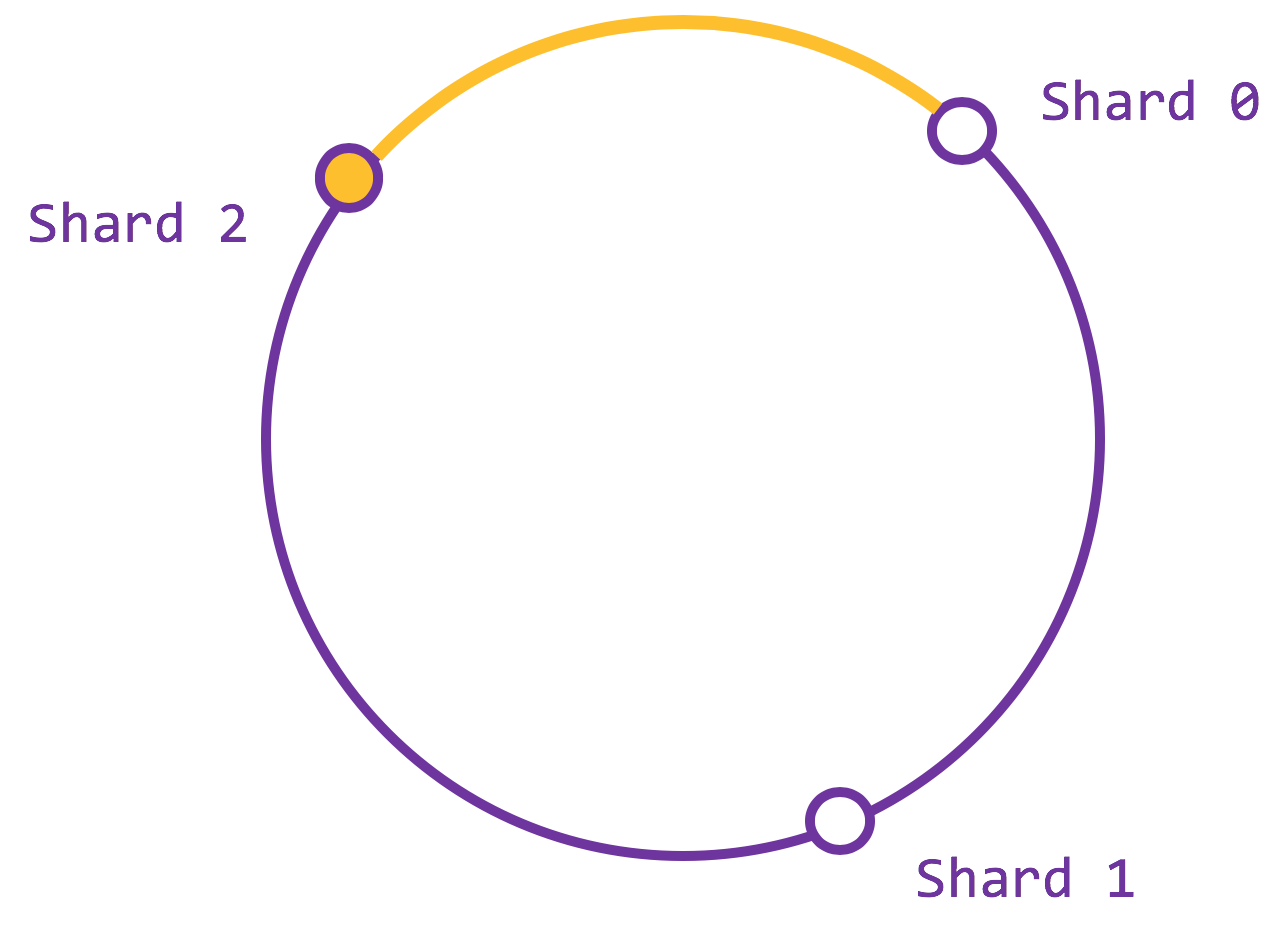
You have a ring that corresponds to the range [0, 1). With your favorite hashing function and modulo operation, each partition key and each shard corresponds to a point on this ring. The assignment is done by walking the ring counterclockwise and the first shard you meet is the shard you go. If a new shard is provisioned, say shard 2, then only the highlighted arc needs to be redistributed from shard 1 to 2. Even better, such redistribution could be done asynchronously in the background, so that shard 1 continues to serve while shard 2 ramps up with the highlighted arc. When shard 2 is ready, it atomically joins the set, and all traffics flows accordingly, given the hashing scheme presented.
Replication
Sharding introduces a new challenge. If each shard has a failure rate of p, which means a probability of (1-p) of being up and running, and the storage is partitioned into n shards, then the chance of the storage being failure free is (1-p)^n, assuming independent failures. A large n means some failure is almost always guaranteed, and that any clients hitting on those keys on the failed shard will also fail.
To increase the availability of the sharded storage, we could replicate each shard independently as Replicating State Machines (RSM). The idea is that if all operations are deterministic, we could model each replica as a state machine such that by replicating the operations in the same order, states are also replicated. Popular algorithms include Raft, Paxos, Viewstamp Replication, where they all have a concept of a master/leader to process all reads and writes. Quorum-based replication often uses the client as the coordinator rather than using server-side nodes. Quorum-based replications are strongly consistent if every quorum (read or write) intersects with every write quorum, which guarantees that at least one node has seen the latest write.
Load Balancers
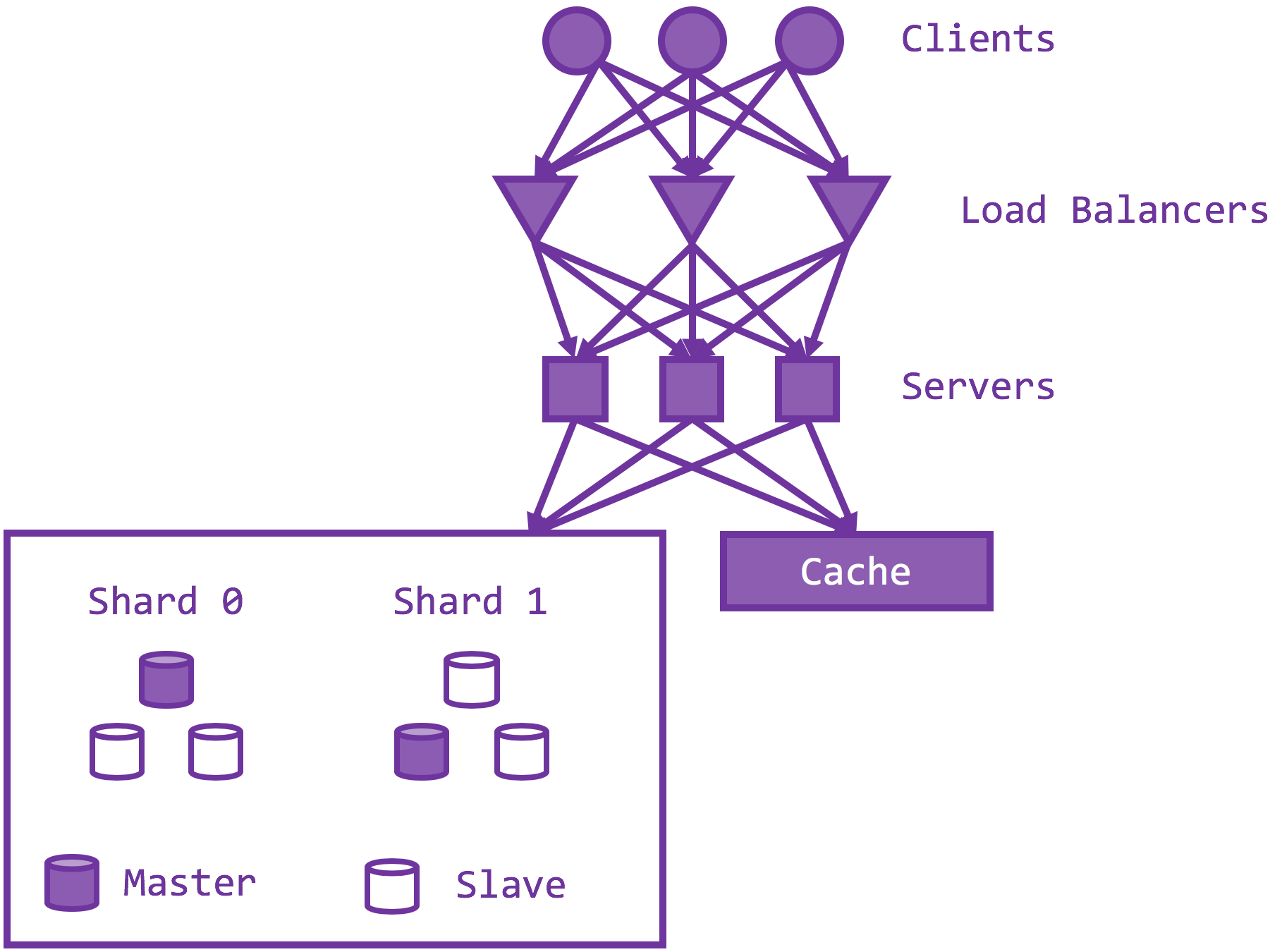
Recall that there is one load balancer (LB) as a reverse proxy on top of the set of API servers. What if the load balancer fails, or if the load balancer becomes the system bottleneck? In essence, one needs an LB cluster, and each LB could independently route to all API server. But how do you load balance on load balancers? The answer is to leverage multiple DNS A records such as the following
1
2
3
192.0.2.1 A example.com
192.0.2.2 A example.com
192.0.2.3 A example.com
What if the DNS server is down? The good news is that the DNS responses are cached (TTL) almost everywhere. The bad news is that all bets are off when caches expired and the DNS server is still down.
Deeper Pipeline: Services
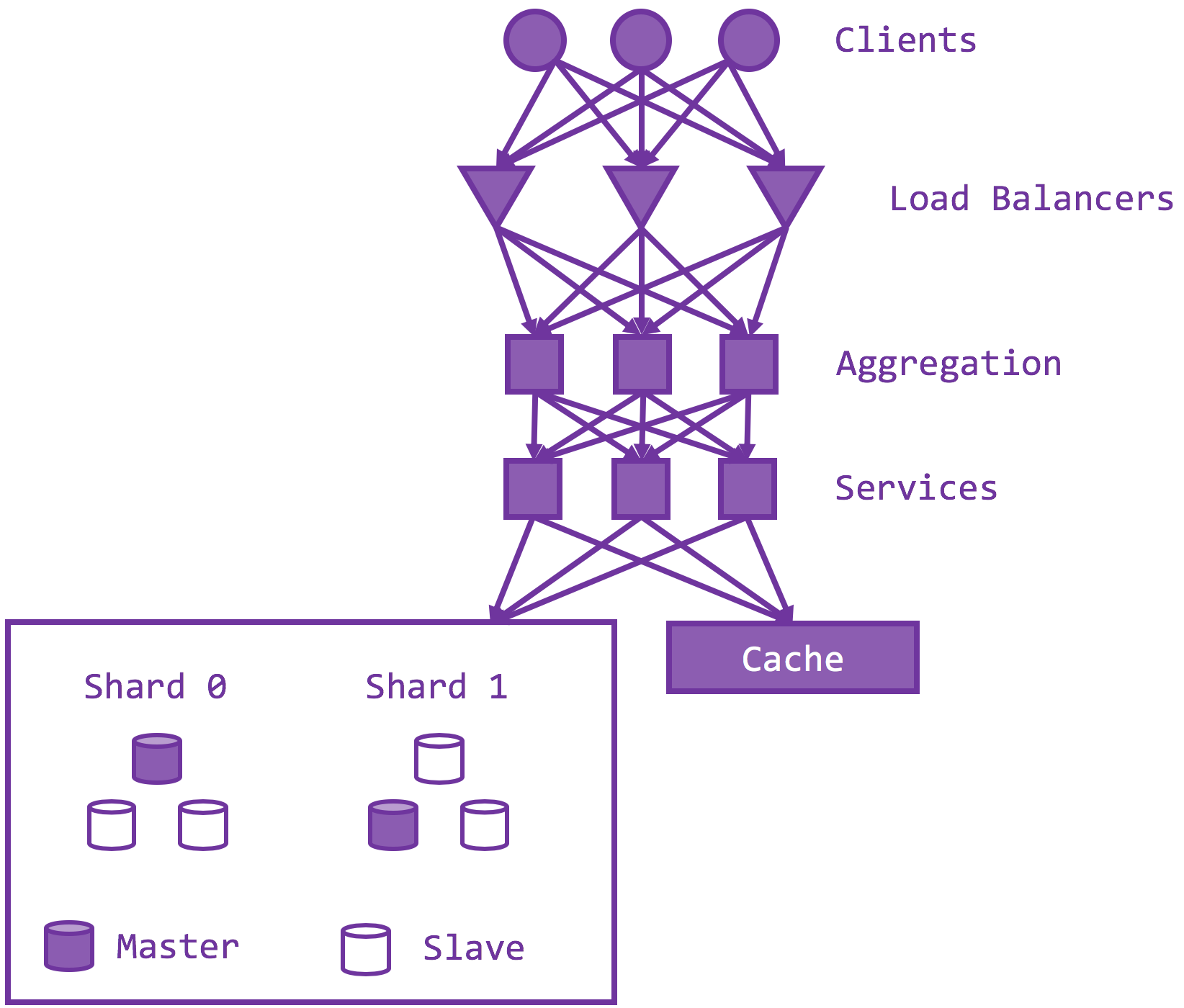
If you remember anything from the fetch-decode-execute cycles from your pipelined processor, you know the pipeline that splits the processor into stages reduces the latency of each stage, so the processor can be clocked at a much higher frequency and hence higher throughput. The same principle applies in the server architecture. Instead of having the API server do all the work, build a pipeline of aggregation and services. A service might depend on other services, meaning a service backend might become the service frontend of other services. Then you need to deal with service discovery, authentication, internal load balancing, etc. Perhaps Istio is worth considering. Take another look at the graph. There is no wonder why it is called a service mesh, with everything tied to everything.
But how do you scale those services behind a service? If the recursive nature is still not clear, read this passage front the top.