Charles Xu
Essays, books, wiki on technologies, career, markets, and more.
Archive of posts with category 'llm'
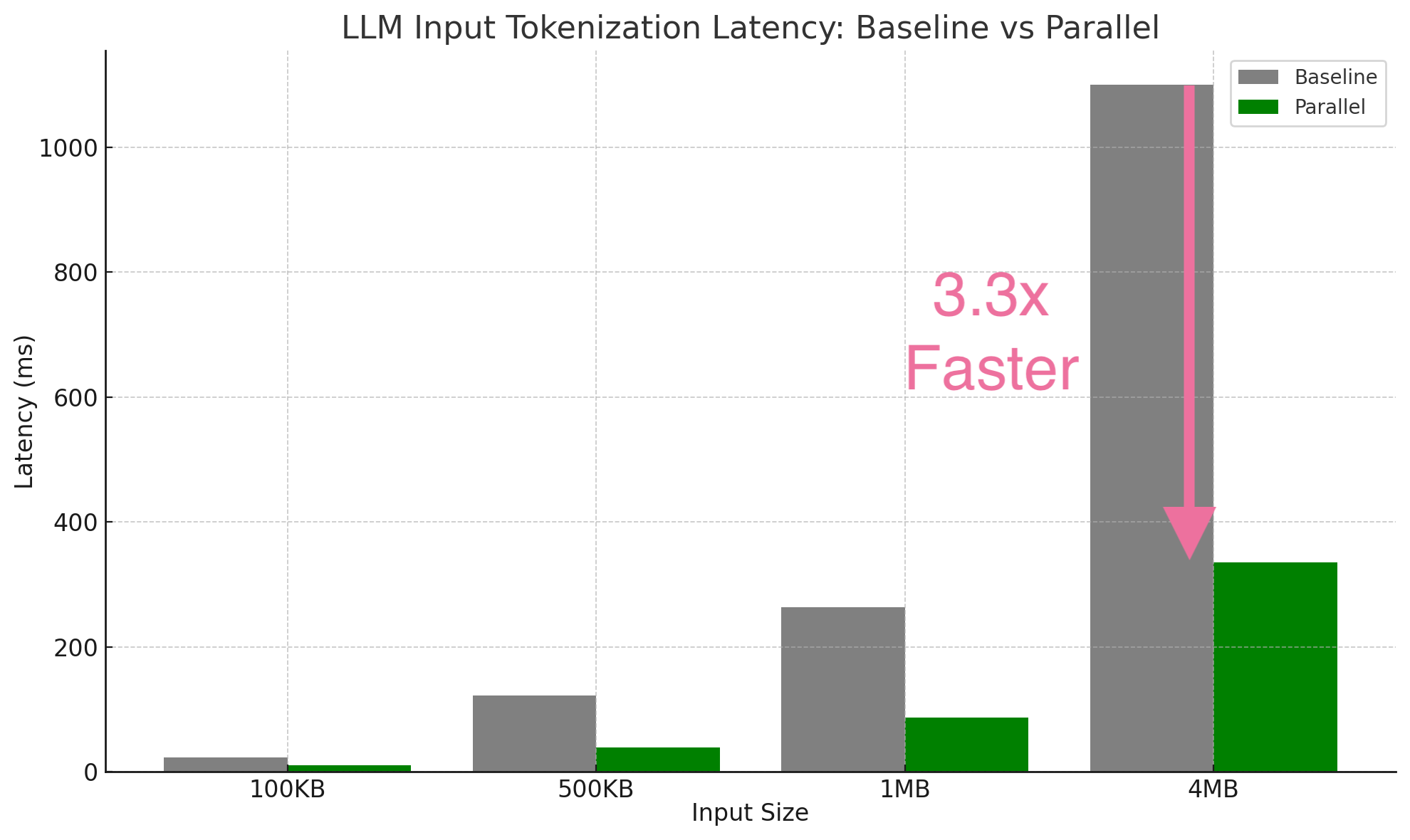
I made HuggingFace tokenizers 3.3x faster by parallelizing single-input tokenization with overlapping chunks, zero-copy offset operations, SIMD-accelerated boundary detection, and cache-hierarchy-aware chunking. The result is bit-identical to serial encoding. Fast...
Many inference speedup techniques mirror the classic systems regime—such as caching, paging, tiling, pipelining, and speculative execution (e.g. branch prediction and cache prefetch). Speculative decoding, generalizing speculative execution to stochastic...
In the multi-head attention mechanism, why after reshaping the projection matrices for Q/K/V from 3 dimensions to 4, we need to transpose the tokens dimension with the heads dimension?